Prepare Dataset Step-by-Step
About
Prepare Dataset Step-by-Step is designed to guide users step-by-step through preparing a dataset in accordance with the Sparc Dataset Structure (SDS) without the need for documentation or prior knowledge. After preparing your dataset you will be guided through sharing it on the SPARC Portal or a generalist repository like Zenodo.
If you are a SPARC-funded researcher it is mandatory that you share the dataset on the SPARC Portal.
Navigating to the Prepare Dataset Step-by-Step feature
On the landing page find the Prepare Dataset Step-by-Step card and click it.
Using the Prepare Dataset Step-by-Step feature
On the first page you have the option to Prepare and optionally share a new dataset or Continue a dataset saved in SODA. Read below to learn more about each option.
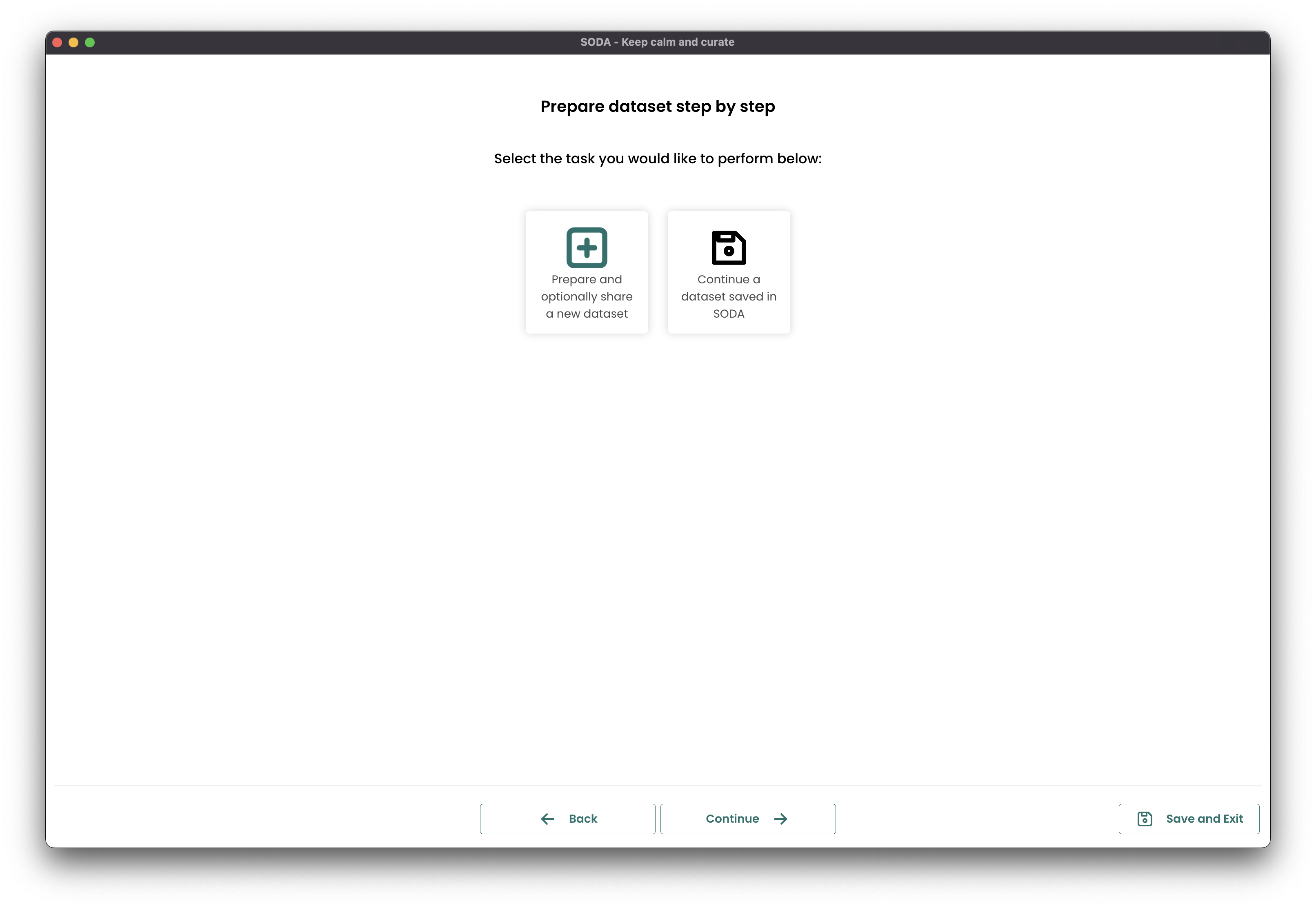
Prepare and optionally share a new dataset
Select this option if you want to begin preparing a dataset for sharing. At the end of the preparation process, you will be able to share it on the SPARC Portal or a generalist repository like Zenodo if you should choose. While preparing your dataset, SODA will guide you through three main steps:
- Dataset Structure: The SDS requires all dataset files to be organized into specific folders and be accompanied by a manifest file that describes their contents. SODA will help you create a compliant structure and manifest file.
- Dataset Metadata: You will be asked to provide metadata for your dataset in order to make it compliant with the Sparc Dataset Structure (SDS). This metadata will include key information that describes your data such as information about the subjects, the data collection process, and more.
- Generate Dataset: You will be assisted in generating and optionally sharing your SDS compliant dataset to a repository of your choosing. If you are a SPARC-funded researcher you will want to share it on Pennsieve. If you are interested in creating a compliant dataset but not necessarily in sharing it on the SPARC Portal, you can choose to generate the dataset on your local computer and share it on a generalist repository like Zenodo.
While preparing your dataset, you can save your progress at any time. This will allow you to continue working on your dataset later without losing any of the work you have done so far.
To do this, simply click the Save & Exit button that appears at the bottom right of the page while preparing your dataset.
SODA will never modify your local data files. Any changes (file renaming, adding metadata files, etc.) will only be reflected on the dataset that is generated on Pennsieve.
Continue a dataset saved in SODA
Select this option if you want to continue working on a dataset previously started and saved in SODA. You will see a list of datasets that you have saved in SODA. Click on the dataset you want to continue working on, and SODA will take you to the step where you left off.